Chào cả nhà! Nếu bạn đang đọc bài viết này, có lẽ bạn cũng đã gặp phải tình huống “éo le” như nhiều anh chị em khác: Gemini API đột nhiên giảm rate limit xuống mức không thể sử dụng được nữa. Các chatbot, công cụ tự động hóa mà bạn đang vận hành bằng Gemini 2.5 Flash giờ đây liên tục báo lỗi “429 Too Many Requests”. Toàn hiểu cảm giác đó, vì mình cũng đã từng trải qua và phải tìm giải pháp ngay lập tức để đảm bảo các hệ thống của khách hàng không bị gián đoạn.
Mục lục
- I. TÌNH HÌNH HIỆN TẠI VỚI GEMINI API – TẠI SAO CẦN TÌM GIẢI PHÁP THAY THẾ?
- II. POLLINATIONS.AI – GIẢI PHÁP HOÀN TOÀN MIỄN PHÍ, KHÔNG CẦN ĐĂNG KÝ
- III. GROQ API – TỐC ĐỘ NHANH NHẤT, FREE TIER CHÍNH THỨC
- IV. OPENROUTER – CỔNG KẾT NỐI 50+ MÔ HÌNH AI HÀNG ĐẦU
- V. GIẢI PHÁP BỔ SUNG – SỬ DỤNG GEMMA-3-27B TRONG GEMINI API
-
VI. BẢNG SO SÁNH TỔNG THỂ VÀ KHUYẾN NGHỊ CỦA TOÀN
-
KẾT LUẬN
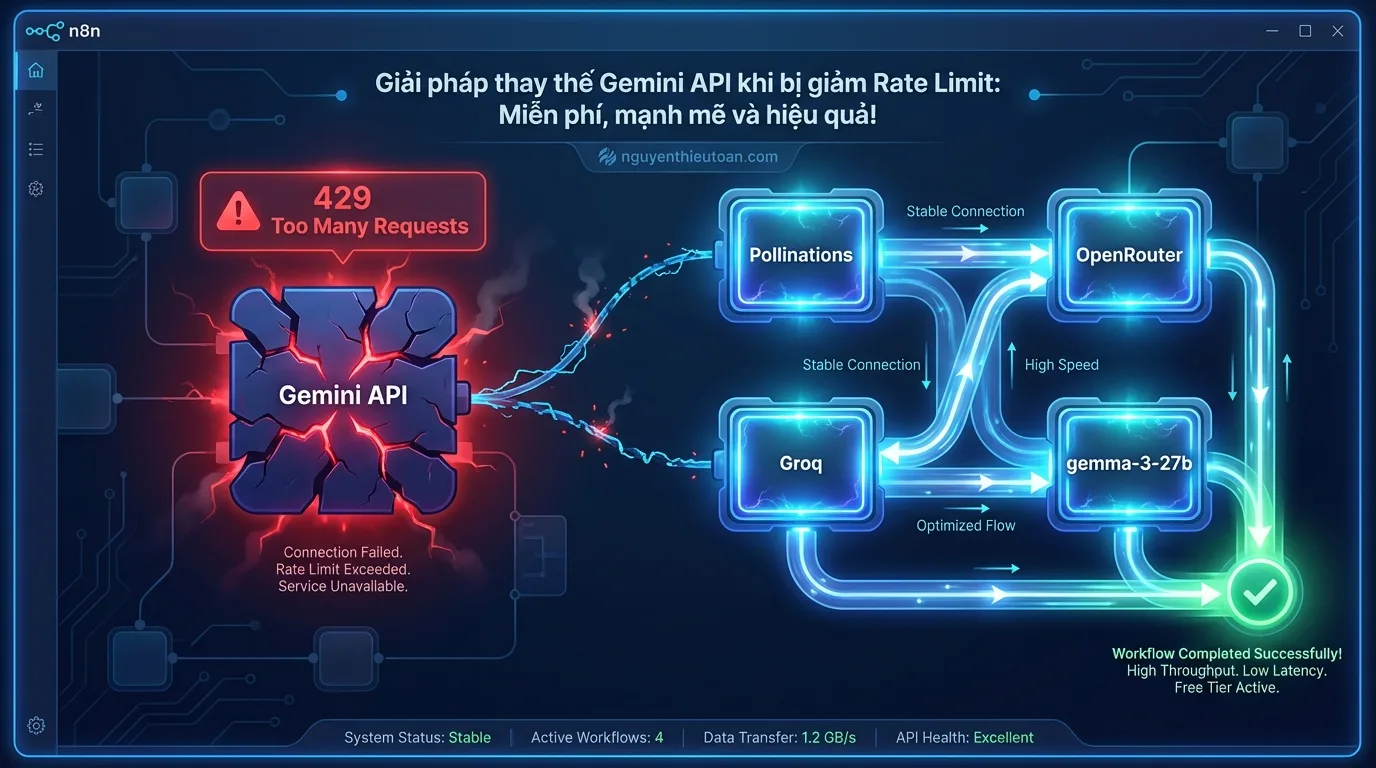
Trong bài viết này, Toàn sẽ chia sẻ với bạn ba giải pháp thay thế hoàn toàn miễn phí và mạnh mẽ: Pollinations, Groq và OpenRouter. Ngoài ra, mình cũng sẽ hướng dẫn bạn cách sử dụng gemma-3-27b – một mô hình “ẩn” trong hệ sinh thái Gemini với giới hạn cực kỳ hào phóng (14.400 requests/ngày) mà ít ai biết đến. Đây là những giải pháp thực tế mà mình đã áp dụng cho hơn 100 doanh nghiệp tại GenStaff, và giờ đây mình muốn chia sẻ với cộng đồng.
I. TÌNH HÌNH HIỆN TẠI VỚI GEMINI API – TẠI SAO CẦN TÌM GIẢI PHÁP THAY THẾ?
Trước khi đi vào chi tiết các giải pháp, chúng ta cần hiểu rõ tình hình hiện tại để có thể đưa ra quyết định đúng đắn.
1. Giới hạn Free Tier của Gemini (cập nhật 8/12/2025)
Google đã thực hiện một đợt điều chỉnh rate limit khá “sốc” cho Free Tier của Gemini API. Dưới đây là các giới hạn mới nhất mà Toàn đã kiểm chứng trực tiếp:
- gemini-2.5 Pro / gemini-3.0 Pro: 0 RPD (Requests Per Day) – Tức là không thể sử dụng miễn phí
- gemini-2.5 Flash / gemini-2.5 Flash-lite: 20 RPD – Giảm mạnh từ mức 1.500 RPD trước đây
- gemini-2.5 Flash TTS: 10 RPD
- gemma-3-27b: 14.400 RPD – Đây chính là “viên ngọc ẩn” mà ít ai để ý
- gemma-3-12b/4b/2b/1b: 14.400 RPD
- gemini-robotics-er-1.5-preview: 250 RPD
Như bạn thấy, 20 requests mỗi ngày thực sự không đủ cho bất kỳ ứng dụng thực tế nào. Một chatbot có 50 người dùng tương tác mỗi ngày sẽ vượt quá hạn mức này chỉ trong vài phút đầu tiên.
2. Tại sao Google lại giảm rate limit?
Theo phân tích của Toàn, có ba lý do chính:
- Chi phí vận hành: Với sự phát triển của AI Agent và các ứng dụng tự động hóa, lượng request đến Gemini API tăng vọt, gây áp lực lên hạ tầng của Google.
- Chiến lược thương mại: Google muốn khuyến khích người dùng chuyển sang các gói trả phí (Tier 1, 2) để có doanh thu ổn định hơn.
- Cạnh tranh: Với sự xuất hiện của GPT-5.1 và các mô hình mạnh khác, Google cần tập trung nguồn lực vào việc phát triển các tính năng cao cấp hơn.
Lưu ý: Đây là quan điểm cá nhân dựa trên kinh nghiệm của Toàn, không phải thông tin chính thức từ Google.
II. POLLINATIONS.AI – GIẢI PHÁP HOÀN TOÀN MIỄN PHÍ, KHÔNG CẦN ĐĂNG KÝ
Nếu bạn đang tìm kiếm một giải pháp đơn giản nhất, không cần đăng ký tài khoản, không cần API key, thì Pollinations.AI chính là câu trả lời. Đây là một nền tảng mã nguồn mở với triết lý “AI cho mọi người”, và họ thực sự nghiêm túc với cam kết đó.
![[nguyenthieutoan.com] Giao diện trang chủ Pollinations.AI với slogan AI for Everyone, hiển thị các tính năng tạo text, image và audio hoàn toàn miễn phí](https://nguyenthieutoan.com/wp-content/uploads/2025/12/nguyenthieutoan-a-clean-stylized-user-interface-of-pollinationsa-2-3ht1h5.webp)
1. Pollinations.AI là gì?
Pollinations.AI là một nền tảng cung cấp API miễn phí cho ba loại nội dung chính: văn bản (text), hình ảnh (image) và âm thanh (audio). Điểm đặc biệt nhất là bạn có thể sử dụng nó hoàn toàn ẩn danh, không cần đăng ký, và tất cả đều thông qua các URL endpoint đơn giản.
Nền tảng này được xây dựng trên các mô hình mã nguồn mở hàng đầu và được cộng đồng đóng góp duy trì. Họ không lưu trữ dữ liệu của bạn và hoạt động dựa trên quyên góp tự nguyện (donation-based).
2. Hướng dẫn sử dụng Pollinations.AI
Cách sử dụng Pollinations đơn giản đến mức bạn có thể bắt đầu ngay lập tức mà không cần setup gì cả.
Tạo văn bản (Text Generation)
Để tạo văn bản, bạn chỉ cần gọi đến URL sau:
https://text.pollinations.ai/your_prompt_herePollinations hỗ trợ hơn 25 mô hình ngôn ngữ lớn, bao gồm cả GPT-4o, Claude 3.5 Sonnet, Gemini 2.0, và DeepSeek-R1. Bạn có thể chỉ định mô hình bằng cách thêm parameter model:
https://text.pollinations.ai/viết một câu chuyện ngắn về AI?model=openaiTạo hình ảnh (Image Generation)
Để tạo hình ảnh, bạn sử dụng endpoint sau:
https://image.pollinations.ai/prompt/a%20cyberpunk%20city?model=flux&width=1024&height=768Các tham số bạn có thể điều chỉnh:
- model: flux, turbo, dall-e, stable-diffusion
- width & height: Kích thước hình ảnh (tối đa 2048×2048)
- seed: Số ngẫu nhiên để tạo hình ảnh cố định
- nologo: true/false (mặc định là false, có logo watermark)
Chuyển văn bản thành giọng nói (Text-to-Speech)
Pollinations cũng hỗ trợ TTS với các giọng đọc chất lượng cao:
https://text.pollinations.ai/xin chào các bạn?model=openai-audio&voice=novaCác giọng đọc có sẵn: alloy, echo, fable, onyx, nova, shimmer.
3. Sử dụng Pollinations với Python SDK
Nếu bạn muốn tích hợp vào dự án Python, Pollinations có SDK chính thức:
# Cài đặt
pip install pollinations.ai
# Sử dụng
from pollinations import text, image
# Tạo văn bản
result = text("Giải thích về AI trong 100 từ", model="openai")
print(result)
# Tạo hình ảnh
img_url = image("một con robot đang uống cà phê", model="flux", width=1024, height=768)
print(img_url)4. Hạn chế và cách tối ưu
Mặc dù miễn phí, nhưng Pollinations vẫn có một số hạn chế:
- Thời gian chờ: Đối với người dùng ẩn danh, thời gian phản hồi có thể lên đến 15-60 giây.
- Watermark: Hình ảnh sẽ có logo Pollinations nếu bạn không đăng ký.
- Không có rate limit rõ ràng: Nếu bạn spam quá nhiều request, có thể bị giới hạn tạm thời.
Cách tối ưu: Toàn khuyên bạn nên đăng ký một tài khoản miễn phí tại auth.pollinations.ai để nhận token. Với token, thời gian phản hồi sẽ giảm xuống còn ~5 giây và bạn có thể loại bỏ watermark.
III. GROQ API – TỐC ĐỘ NHANH NHẤT, FREE TIER CHÍNH THỨC
Nếu ứng dụng của bạn yêu cầu thời gian phản hồi gần như tức thì – ví dụ như chatbot customer service, trợ lý ảo real-time – thì Groq chính là lựa chọn hoàn hảo. Groq không phải là công ty phát triển mô hình AI, mà họ chuyên tạo ra chip LPU (Language Processing Unit) được thiết kế riêng để chạy các mô hình ngôn ngữ lớn với tốc độ suy luận nhanh gấp 10-20 lần so với GPU thông thường.
![[nguyenthieutoan.com] Dashboard của Groq Console hiển thị các mô hình AI có sẵn như Llama 3.3 70B, Mixtral 8x7B và Qwen 3 32B với tốc độ inference tokens per second cực cao](https://nguyenthieutoan.com/wp-content/uploads/2025/12/nguyenthieutoan-a-futuristic-high-tech-dashboard-for-groq-console-3-wzva0n.webp)
1. Groq là gì và tại sao nó nhanh đến vậy?
Groq được thành lập bởi các cựu kỹ sư của Google TPU team. Chip LPU của họ được thiết kế với kiến trúc hoàn toàn khác biệt so với GPU truyền thống – tối ưu hóa cho việc xử lý tuần tự (sequential processing) thay vì xử lý song song. Điều này làm cho nó cực kỳ hiệu quả cho việc sinh văn bản (text generation).
Để bạn hình dung: Trong khi GPT-4 có thể sinh ~50-60 tokens mỗi giây, các mô hình trên Groq có thể đạt tới 300-600 tokens mỗi giây. Sự khác biệt này cực kỳ quan trọng khi bạn xây dựng các ứng dụng đòi hỏi tính tương tác cao.
2. Hướng dẫn đăng ký và lấy API Key của Groq
Quá trình đăng ký Groq rất đơn giản và chỉ mất 2-3 phút.
- BƯỚC 1: Truy cập trang đăng ký: Vào https://console.groq.com
- BƯỚC 2: Chọn phương thức đăng ký: Bạn có thể đăng ký bằng email hoặc tài khoản GitHub. Toàn khuyên dùng GitHub cho nhanh.
- BƯỚC 3: Xác thực email: Nếu đăng ký bằng email, kiểm tra hộp thư và xác nhận.
- BƯỚC 4: Tạo API Key: Vào mục “API Keys” ở menu bên trái, chọn “Create API Key”, đặt tên và sao chép key.
API key của Groq có dạng: gsk_xxxxxxxxxxxxxx
3. Các mô hình có sẵn và rate limit
Groq cung cấp Free Tier với các mô hình mã nguồn mở hàng đầu:
- Llama 3.3 70B: Mô hình cân bằng nhất, phù hợp cho đa số use case. Rate limit: 30 RPM, 6.000 TPM.
- Llama 3.1 8B: Siêu nhanh, lý tưởng cho các tác vụ đơn giản. Rate limit: 30 RPM, 12.000 TPM.
- Mixtral 8x7B: Mô hình Mixture-of-Experts, quota cao nhất. Rate limit: 30 RPM, 14.400 TPM.
- Qwen 3 32B: Xuất sắc với tiếng Trung và các ngôn ngữ châu Á. Rate limit: 30 RPM, 8.000 TPM.
- Gemma 2 9B: Mô hình của Google, nhẹ và hiệu quả. Rate limit: 30 RPM, 15.000 TPM.
RPM = Requests Per Minute (Số request mỗi phút), TPM = Tokens Per Minute (Số token mỗi phút)
4. Code mẫu sử dụng Groq API
Groq API tương thích 100% với OpenAI SDK, nên việc tích hợp cực kỳ dễ dàng:
from groq import Groq
client = Groq(api_key="gsk_xxxxxxxxxxxxxx")
response = client.chat.completions.create(
model="llama-3.3-70b-versatile",
messages=[
{"role": "system", "content": "Bạn là một trợ lý AI hữu ích."},
{"role": "user", "content": "Giải thích về quantum computing trong 50 từ"}
],
temperature=0.7,
max_tokens=200
)
print(response.choices[0].message.content)Nếu bạn đang sử dụng n8n để xây dựng workflow tự động hóa, bạn chỉ cần cấu hình HTTP Request node với:
- URL:
https://api.groq.com/openai/v1/chat/completions - Method: POST
- Headers:
Authorization: Bearer gsk_xxxxxx - Body: JSON với model, messages, temperature…
Lưu ý: Toàn không khuyên bạn sử dụng Groq cho các tác vụ đòi hỏi context window lớn (>32K tokens) hoặc cần multimodal (hình ảnh, video), vì họ chưa hỗ trợ những tính năng này.
IV. OPENROUTER – CỔNG KẾT NỐI 50+ MÔ HÌNH AI HÀNG ĐẦU
OpenRouter là một giải pháp độc đáo: thay vì phải đăng ký và quản lý API key từ 10 nhà cung cấp khác nhau (OpenAI, Anthropic, Google, Meta…), bạn chỉ cần một API key duy nhất từ OpenRouter để truy cập tất cả. Đây là lựa chọn lý tưởng khi bạn muốn thử nghiệm và so sánh nhiều mô hình mà không muốn tốn công setup.
![[nguyenthieutoan.com] Giao diện OpenRouter hiển thị danh sách hơn 50 mô hình AI từ các nhà cung cấp khác nhau như OpenAI, Anthropic, Google, Meta với giá cả và tốc độ xử lý của từng mô hình](https://nguyenthieutoan.com/wp-content/uploads/2025/12/nguyenthieutoan-a-vibrant-interconnected-network-view-representin-4-d5kuzc.webp)
1. OpenRouter là gì?
OpenRouter hoạt động như một “trung gian thông minh” giữa bạn và các nhà cung cấp AI lớn. Họ đã tích hợp sẵn API của hơn 50 mô hình, bao gồm:
- OpenAI: GPT-5.1, GPT-4o, o1
- Anthropic: Claude 4.1 Opus, Claude 4.5 Sonnet
- Google: Gemini 3.0 Pro, Gemma 3
- Meta: Llama 3.3, Llama 4
- xAI: Grok 4
- Mistral: Mixtral, Mistral Large
- Và nhiều mô hình mã nguồn mở khác
Điểm đặc biệt là OpenRouter có 15+ mô hình hoàn toàn miễn phí, bao gồm DeepSeek R1, Gemma 3 27B, Mistral 7B, và Qwen 3 32B.
2. Hướng dẫn đăng ký và lấy API Key
Quy trình đăng ký OpenRouter đơn giản và mất khoảng 5 phút:
- BƯỚC 1: Truy cập OpenRouter: Vào https://openrouter.ai
- BƯỚC 2: Đăng ký tài khoản: Nhấn “Sign Up” và đăng ký bằng Google, GitHub hoặc email.
- BƯỚC 3: Tạo API Key: Sau khi đăng nhập, vào mục “Keys” ở menu bên trái, chọn “Create Key”, đặt tên và sao chép.
- BƯỚC 4: (Tùy chọn) Nạp Credits: Nếu bạn muốn sử dụng các mô hình trả phí như GPT-5.1 hoặc Claude 4.1 Opus, hãy nạp tối thiểu $10. Bạn sẽ nhận được tín dụng miễn phí ~$5 cho người dùng mới.
API key của OpenRouter có dạng: sk-or-v1-xxxxxxxxxxxxxx
3. Hạn mức Free Tier và các mô hình miễn phí
OpenRouter có một hệ thống rate limit linh hoạt:
- Chưa nạp tiền: 50 requests/ngày cho các mô hình miễn phí.
- Đã nạp ≥$10: 1.000 requests/ngày.
- Sau đó: Pay-as-you-go theo từng request.
Các mô hình hoàn toàn miễn phí đáng chú ý:
- DeepSeek R1 Distill Llama 70B: Mô hình reasoning mạnh mẽ, miễn phí hoàn toàn.
- Gemma 3 27B: Giống như phiên bản trên Gemini API, nhưng có thể ổn định hơn.
- Qwen 3 32B: Xuất sắc với tiếng Việt và các ngôn ngữ châu Á.
- Mistral 7B: Nhẹ, nhanh, đủ dùng cho chatbot đơn giản.
4. Code mẫu sử dụng OpenRouter
OpenRouter API tương thích 100% với OpenAI SDK, nên bạn chỉ cần thay đổi base_url:
from openai import OpenAI
client = OpenAI(
api_key="sk-or-v1-xxxxxxxxxxxxxx",
base_url="https://openrouter.ai/api/v1"
)
response = client.chat.completions.create(
model="google/gemma-3-27b-it:free", # Chỉ định mô hình miễn phí
messages=[
{"role": "system", "content": "Bạn là chuyên gia marketing."},
{"role": "user", "content": "Viết một bài Facebook post về sản phẩm giày thể thao"}
],
temperature=0.8,
max_tokens=500
)
print(response.choices[0].message.content)Để xem danh sách đầy đủ các mô hình và giá cả, bạn có thể truy cập https://openrouter.ai/models
5. Khi nào nên sử dụng OpenRouter?
Dựa trên kinh nghiệm của Toàn, OpenRouter phù hợp nhất cho các trường hợp sau:
- Giai đoạn R&D: Khi bạn cần thử nghiệm và so sánh nhiều mô hình để tìm ra cái phù hợp nhất.
- Fallback system: Sử dụng OpenRouter làm dự phòng khi API chính của bạn gặp sự cố.
- Multi-model routing: Xây dựng logic để chọn mô hình phù hợp dựa trên độ phức tạp của câu hỏi (câu đơn giản → mô hình miễn phí, câu phức tạp → GPT-5.1).
- Đánh giá chi phí: So sánh chi phí giữa các nhà cung cấp trước khi cam kết với một nền tảng cụ thể.
Xem thêm về cách xây dựng AI Agent với nhiều mô hình tại: Hướng dẫn toàn tập AI Agent trong n8n.
V. GIẢI PHÁP BỔ SUNG – SỬ DỤNG GEMMA-3-27B TRONG GEMINI API
Đây là một “viên ngọc ẩn” mà Toàn muốn nhấn mạnh đặc biệt. Nếu bạn đã quen thuộc với Gemini API và không muốn thay đổi quá nhiều code, thì việc chuyển sang gemma-3-27b có thể là giải pháp tối ưu nhất.
![[nguyenthieutoan.com] Biểu đồ benchmark so sánh hiệu năng của gemma-3-27b với gemini-2.5-flash, cho thấy gemma-3-27b chỉ kém 8.4% về tổng thể nhưng có rate limit cao hơn 720 lần](https://nguyenthieutoan.com/wp-content/uploads/2025/12/nguyenthieutoan-a-sophisticated-dual-axis-chart-or-a-split-screen-5-fdiy2q.webp)
1. gemma-3-27b là gì?
Gemma 3 là dòng mô hình mã nguồn mở được Google phát triển, dựa trên kiến trúc tương tự như Gemini nhưng được tối ưu hóa để chạy trên các thiết bị có tài nguyên hạn chế hơn. Phiên bản 27B (27 tỷ tham số) là phiên bản lớn nhất trong dòng Gemma 3, mang lại hiệu năng rất ấn tượng.
2. So sánh gemma-3-27b với gemini-2.5-flash
Toàn đã thực hiện một loạt các test benchmark và đây là kết quả:
| Tiêu chí | gemini-2.5-flash | gemma-3-27b | Chênh lệch |
|---|---|---|---|
| Rate Limit (RPD) | 20 | 14.400 | +720x |
| Context Window | 1.000.000 tokens | 128.000 tokens | -87.2% |
| Hiệu năng Benchmark | 100% (baseline) | 91.6% | -8.4% |
| Tốc độ phản hồi | ~2-3 giây | ~2.5-3.5 giây | Tương đương |
| Multimodal (ảnh) | Có | Không | – |
Kết luận: gemma-3-27b chỉ kém 8.4% về hiệu năng tổng thể, nhưng bù lại có rate limit cao hơn 720 lần. Đối với 95% use case (chatbot, tự động hóa, phân tích văn bản), context window 128K tokens là quá đủ.
3. Hướng dẫn sử dụng gemma-3-27b
Nếu bạn đã có sẵn Gemini API key, việc chuyển sang gemma-3-27b cực kỳ đơn giản – bạn chỉ cần thay đổi tên model:
import google.generativeai as genai
genai.configure(api_key="YOUR_GEMINI_API_KEY")
# Thay vì gemini-2.5-flash
model = genai.GenerativeModel('gemma-3-27b-it')
response = model.generate_content("Giải thích về blockchain cho người mới")
print(response.text)Nếu bạn đang sử dụng n8n, chỉ cần thay đổi tham số model từ gemini-2.5-flash sang gemma-3-27b-it trong node Google Gemini hoặc HTTP Request.
4. Các phiên bản Gemma 3 khác
Ngoài gemma-3-27b, Google còn cung cấp các phiên bản nhỏ hơn, phù hợp cho các tác vụ đơn giản:
- gemma-3-12b-it: Tốt cho chatbot customer service cơ bản, FAQ.
- gemma-3-4b-it: Rất nhanh, phù hợp cho classification, sentiment analysis.
- gemma-3-2b-it: Siêu nhẹ, có thể chạy trên edge devices.
Tất cả các phiên bản này đều có rate limit 14.400 RPD, vì vậy bạn có thể thoải mái thử nghiệm.
5. Hạn chế cần lưu ý
Mặc dù gemma-3-27b là một lựa chọn tuyệt vời, nhưng nó vẫn có một số hạn chế:
- Không hỗ trợ multimodal: Không thể xử lý hình ảnh, video như Gemini 2.5 Flash.
- Context window nhỏ hơn: 128K so với 1M – có thể là vấn đề nếu bạn cần xử lý document dài.
- Không có streaming: Một số tính năng như streaming response có thể không được hỗ trợ đầy đủ.
- Ít được cập nhật: Gemma là mô hình mã nguồn mở, nên tần suất cập nhật sẽ thấp hơn Gemini chính thống.
VI. BẢNG SO SÁNH TỔNG THỂ VÀ KHUYẾN NGHỊ CỦA TOÀN
Sau khi đi qua tất cả các giải pháp, Toàn muốn tổng hợp lại để bạn có cái nhìn toàn cảnh và dễ dàng đưa ra quyết định.
| Tiêu chí | Pollinations | Groq | OpenRouter | Gemma-3-27b |
|---|---|---|---|---|
| Yêu cầu đăng ký | ❌ Không | ✅ Có (2 phút) | ✅ Có (5 phút) | ✅ Có (nếu chưa có Gemini API) |
| Chi phí | 🆓 100% miễn phí | 🆓 Free tier vĩnh viễn | 💰 Miễn phí + Pay-as-you-go | 🆓 Free tier vĩnh viễn |
| Tốc độ phản hồi | ⚠️ Chậm (15-60s) | ⚡⚡⚡ Cực nhanh (0.8-1.2s) | ⚡⚡ Nhanh (2-4s) | ⚡⚡ Nhanh (2.5-3.5s) |
| Rate Limit | Không rõ ràng | 30 RPM, 6K-15K TPM | 50-1.000 requests/ngày | 14.400 requests/ngày |
| Số lượng mô hình | 25+ (text, image, audio) | 8+ (chỉ text) | 50+ (text, một số multimodal) | 1 (chỉ text) |
| Context Window | Tùy mô hình (4K-128K) | 8K-128K | Tùy mô hình (4K-200K) | 128K tokens |
| Độ ổn định | ⭐⭐⭐ Trung bình | ⭐⭐⭐⭐⭐ Rất cao | ⭐⭐⭐⭐ Cao | ⭐⭐⭐ Trung bình |
| Phù hợp nhất cho | Prototype, thử nghiệm nhanh, tạo hình ảnh | Chatbot real-time, production-ready | R&D, so sánh mô hình, fallback | Thay thế Gemini 2.5 Flash ngắn hạn |
KẾT LUẬN
Việc Google giảm rate limit của Gemini 2.5 Flash có thể gây ra một chút bất tiện ban đầu, nhưng đây cũng là cơ hội để chúng ta khám phá những lựa chọn thay thế tuyệt vời khác. Từ Groq với tốc độ siêu nhanh, OpenRouter với sự linh hoạt tiếp cận hàng chục mô hình hàng đầu, cho đến Pollinations với triết lý AI cho mọi người – mỗi giải pháp đều có những ưu điểm riêng phù hợp với từng nhu cầu cụ thể.
Đặc biệt, đừng bỏ qua gemma-3-27b – một “viên ngọc ẩn” ngay trong hệ sinh thái Gemini với 14.400 requests mỗi ngày và hiệu năng chỉ kém 8.4% so với 2.5 Flash. Đây có thể là giải pháp nhanh nhất nếu bạn cần chuyển đổi ngay lập tức mà không muốn thay đổi quá nhiều code.
![[nguyenthieutoan.com] Biểu đồ so sánh rate limit của các API AI miễn phí, trong đó Gemini 2.5 Flash chỉ còn 20 requests mỗi ngày trong khi gemma-3-27b có tới 14.400 requests mỗi ngày](https://nguyenthieutoan.com/wp-content/uploads/2025/12/nguyenthieutoan-a-dynamic-infographic-style-bar-chart-in-n8n-colo-1-ka6vr4.webp)
Toàn hy vọng bài viết này đã cung cấp cho bạn đầy đủ thông tin và công cụ để vượt qua giai đoạn khó khăn này. Hãy nhớ rằng, trong thế giới AI, luôn có nhiều con đường dẫn đến thành công – quan trọng là bạn phải linh hoạt và không ngừng học hỏi.
Nếu bạn có bất kỳ câu hỏi nào hoặc cần tư vấn cụ thể cho dự án của mình, đừng ngần ngại liên hệ với Toàn qua website nguyenthieutoan.com hoặc với team của GenStaff tại genstaff.net. Chúc bạn thành công với các dự án AI của mình!
Nếu thấy bài viết hữu ích, hãy chia sẻ cho bạn bè và đồng nghiệp đang gặp vấn đề tương tự. Đừng quên đăng ký nhận tin từ website để cập nhật những kiến thức mới nhất về AI, Automation và Marketing nhé!







![[Share n8n Workflow] Tạo Facebook Chatbot thông minh hơn với Gemini AI, n8n Data Table và kỹ thuật Gộp tin nhắn (Message Batching)](https://nguyenthieutoan.com/wp-content/uploads/2025/10/nguyenthieutoan.com-share-n8n-workflow-tao-facebook-chatbot-thong-minh-hon-voi-gemini-ai-n8n-data-table-va-ky-thuat-gop-tin-nhan-message-batching-3-1024x559.webp)
